
Database Schema Migrations with Prisma and AWS CloudFormation
Mar 24, 2023

Hagalín Guðmundsson

If you are a developer, you know how important it is to have a smooth process for deploying database migrations. So today let's talk about how you can do that using CloudFormation Custom Resources.
Prisma
First, a brief mention of Prisma. Prisma is an open-source ORM for Node.js and TypeScript that provides a type-safe and intuitive way to work with databases. Prisma is composed of multiple components which includes the Schema, Client, Migrate, CLI etc. We are big fans of the Prisma suite, so we use most of their components extensively, especially Prisma Migrate. It's an excellent tool for managing database migrations because it automatically generates migration scripts based on changes to your database schema.
Ideally then, the migration scripts are kept in your code repository along with your prisma.schema file.
Lambda-Backed CloudFormation Resources
Second, let's summarize a couple of things about CloudFormation Custom Resources. AWS CloudFormation offers a way to extend its capabilities with Custom Resources i.e. allowing you to write custom code that can be executed as part of the stack creation or update process. This is incredibly useful because it means that you can use CloudFormation to deploy and manage your stack, even if you have resources that are not AWS native.
The custom resources are Lambda backed (can also be SNS backed, but we won't be using that here) and we'll be using a helper package to simplify the integration with CloudFormation: cfn-custom-resource
The Target Workflow
Here's the workflow that we want to achieve:
Developer makes changes to the prisma.schema
Regenerate the Prisma Client and do the code changes necessary.
Using the Prisma CLI the developer creates a migration script. Additionally, make any additional changes & test it against your local environment together with the Prisma Client.
Commit and push your code changes along with your migration script to your code repository. Ideally make a pull request to get someone to review your changes.
Once the changes are approved and have been merged, the CI/CD pipeline should take your changes and deploy them to your environments.
This process follows a entity first migration flow. For the remainder of this post then let's expand on the last step of this workflow and see how you can deploy these changes with CloudFormation.
Let's Create a Lambda Function Handler
Here's how that can look in javascript code:
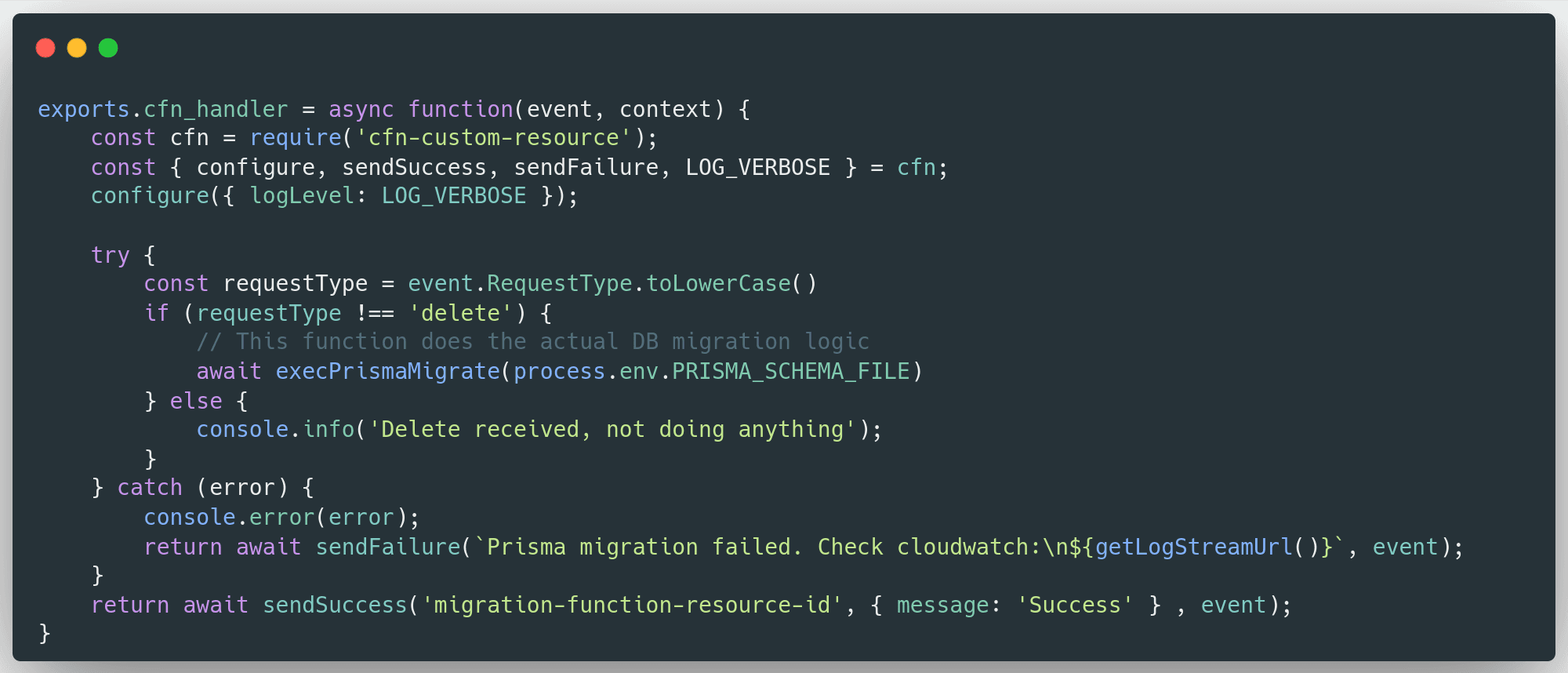
The main point of this code is to wrap the migration logic with some error and success handling for CloudFormation. The actual migration logic would be:
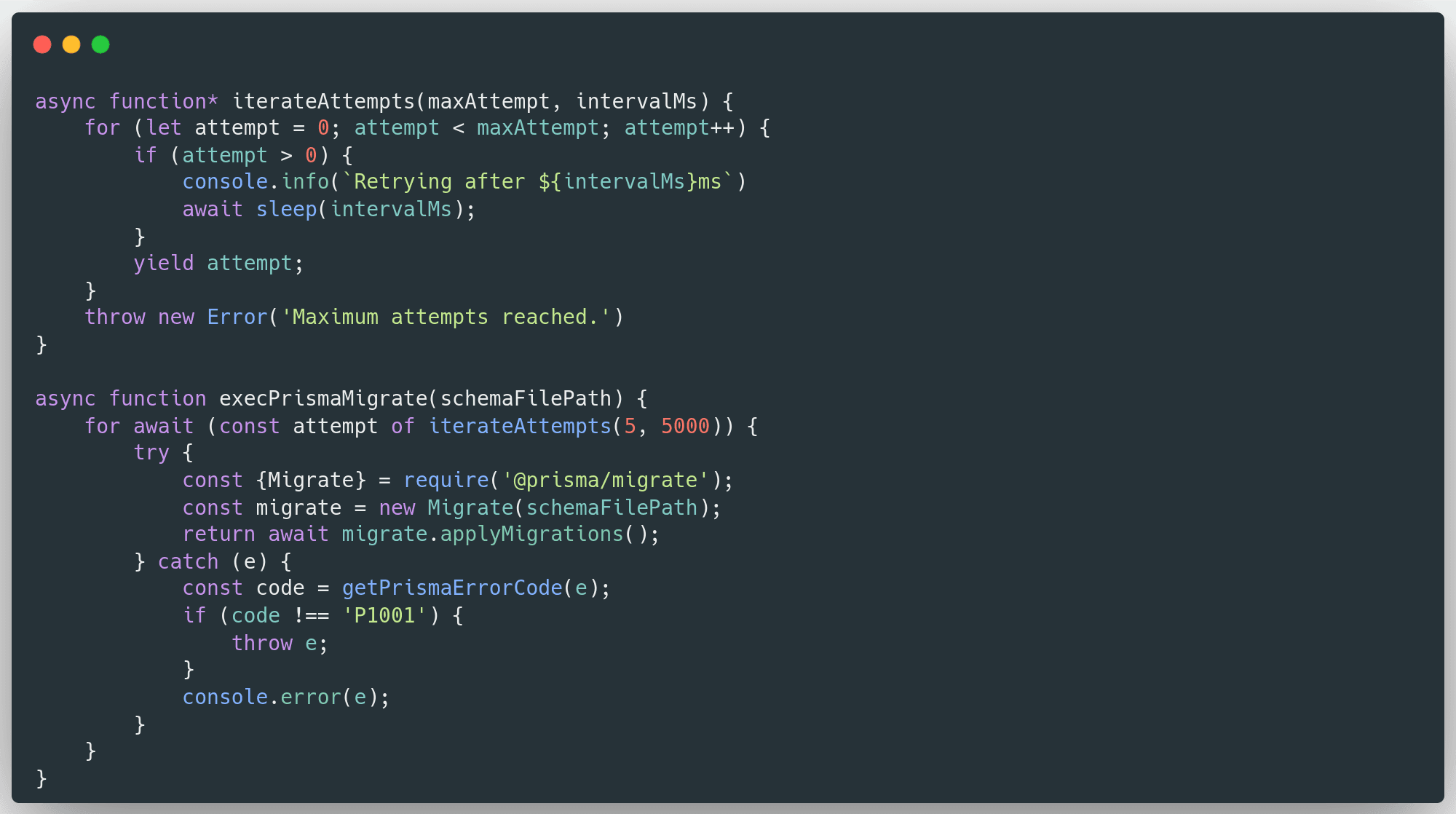
We use an iteration logic which allows for some time for the database becomes responsive (P1001 error code from prisma means that it cant reach the database). This is especially useful if you're using serverless aurora which can scale to 0.
.. And Package it With Docker
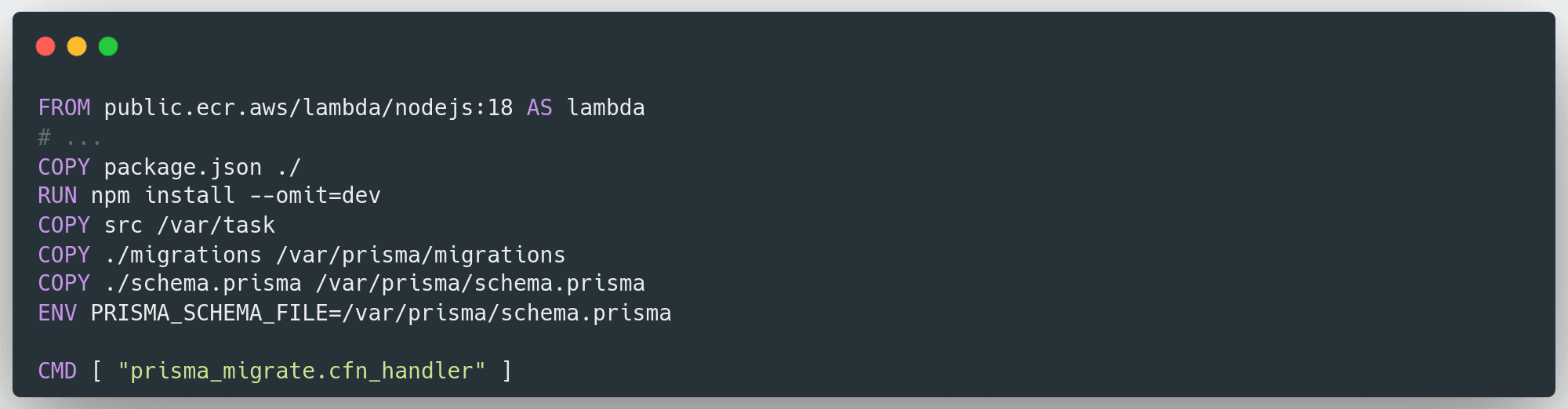
Now you can take your Lambda handler code, prisma.schema file and all the database migration scripts and package it with Docker. Here's a sample snippet for a Dockerfile:
Connect the Lambda with our DB
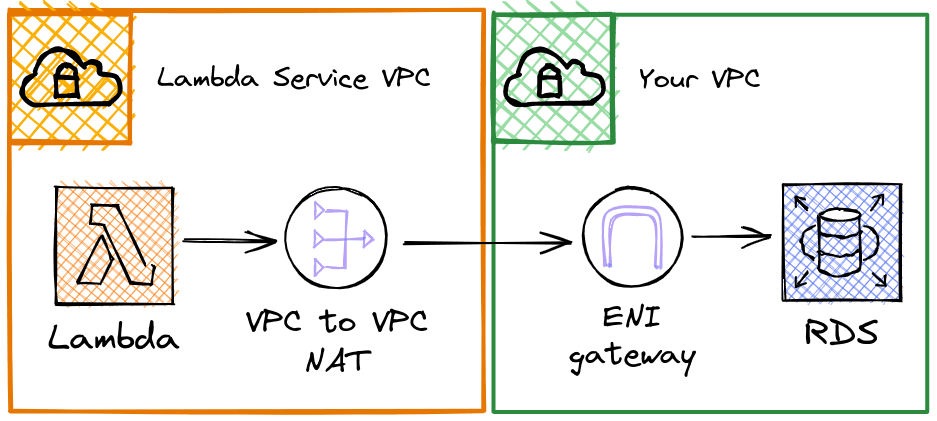
Now Lambda is a service that is entirely managed by AWS, in reality you don't really know where the code is being run. This is problematic since, ideally, you should be hosting your Database inside a private network with no inbound network access. Lambda has a way to work with that HyperPlane ENI, where you give Lambda some VPC configurations (subnet and security group) which you can assume your code will run inside. In reality the Lambda service will create a ENI gateway inside your VPC. So your Lambda runtime environment will send all your network requests over this tunnel. This also means that in order for your Lambda runtime to have access to the internet you need a NAT device on the other end.
Deploy with CloudFormation
Here's an example of a template that templates the Lambda function and the custom resource. This can then be included in your existing template.
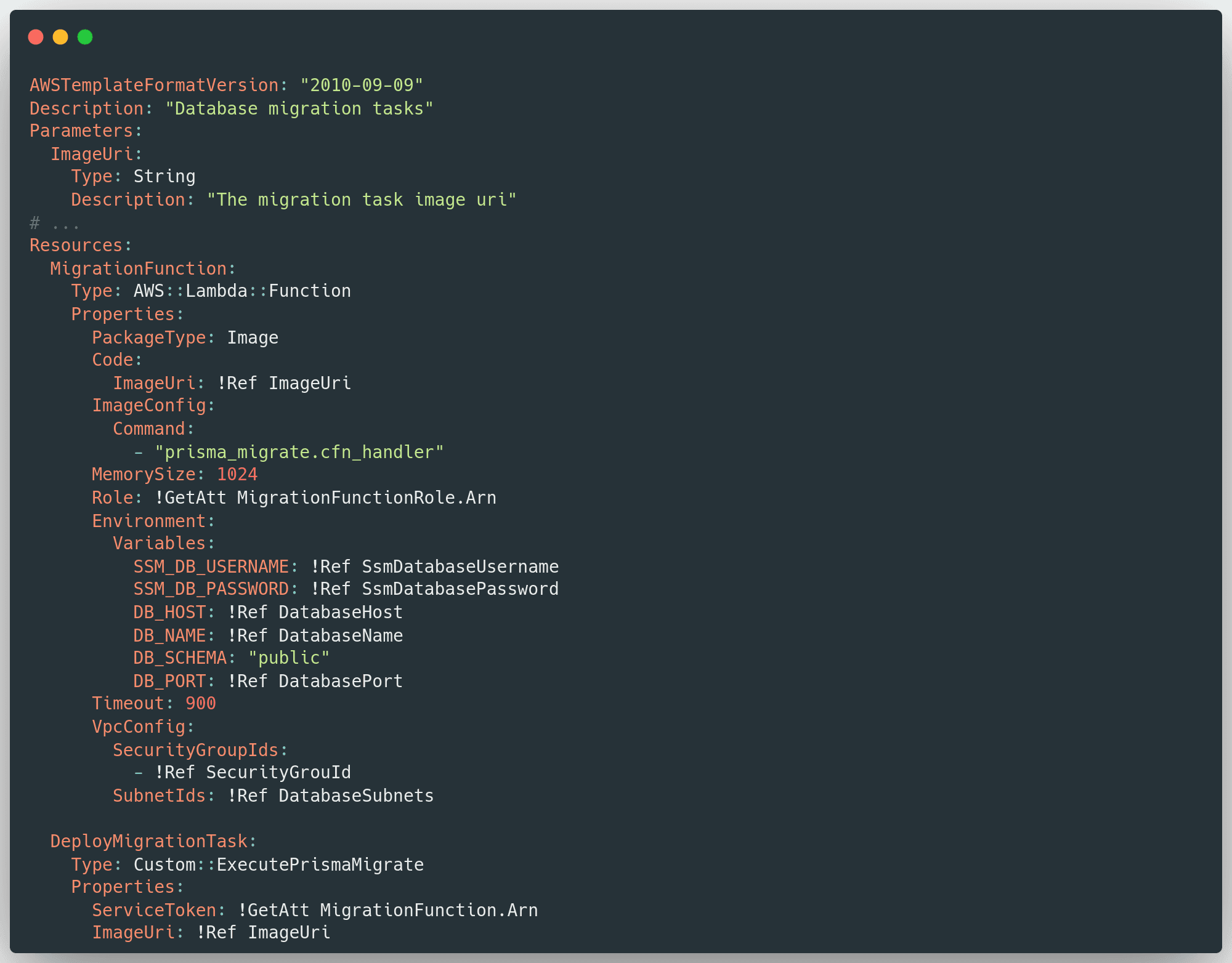
What the !"#$ is with the SSM_ parameters? Well, they are a nice way to share secrets with your Lambda code. We wrote an entire blog post about that here.
Once you've created your change set and started the execution, then the process will go through phases like this:

Integration with CI/CD systems
This of course depends on what CI/CD system you use, and we didn't want to be specific about anything here since it should be really easy to plug this in. But ideally your pipeline just needs to do these two things:
Build the image and push it to ECR
Deploy the cloudformation template with the ECR full imageUri as the input parameter.
Of course we encourage automatic testing of the migration scripts, but we'll save that for another blog post. :)
Limitations
Here we're limited by the amount of time the migration scripts can take. The Lambda has a timeout that can't exceed 900 seconds. So if your database size and/or load is such that the migrations generally exceed that time, then this wouldn't be a good option for you. However you could instead deploy your migration docker image as a ECS Task Definition and set your Lambda function / CloudFormation custom resource to start that as an ECS task. You are not bounded by any timeout limits are except those imposed by your CloudFormation stack options.
Conclusion
We've shown how you can easily package and deploy your database schema changes to your environments by using Prisma Migrate and CloudFormation Custom Resources. With this you'll be able to achieve a very seamless workflow around schema migrations that will boost productivity and make database changes less terrifying for developers. This works great for smaller-medium scaled workloads and especially if you already have prisma in your tool chain.
References
Checkout the full example on GitHub.